Some background: I’ve been an Subversion user for 12 or so years now. I understand the model, I can, with a little patience, get it to dance to my every whim. The model of a centralized bucket of ‘truth’ that I can push changes to from my local working copy is one that clicks with me. My buddy Tim keeps trying to explain the concepts of git, and each time I think I get it a little more, but it’s still pretty intimidating.
My end goals here don’t really seem that crazy:
- Check my site into some form of source control. The server is set up for git already, and not svn, so I figure its time to suck it up & figure this thing out.
- Install hugo on the server. right now i’m running it locally & copying the result up to the server, but I would rather it ran on that end so I didn’t have to muck w/ the copy part, myself.
- Get the site to auto-build on a timer, and when new content is pushed. There are a ton of hooks for various actions in git, and this seems like it should be fairly trivial.
When everyone starts explaining git, one of the first things they do, is to make it very clear that git is not centralized. they draw pictures of little repositories, all peers, all passing changes around, all being happy. I imagine Bob Ross sketching these… “This happy little repository needs some happy little friends to share his changes with!” With this in mind, the model that I thought would be best for me, would be a git repository on the server, and a git repository on my laptop where I like to write. I could then make changes locally, commit them, and push them to the server repository, where they would magically appear, so that hugo could run over them and re-generate my website.
When I started searching for information on how to get my git set up, I came across a wonderful tutorial from Atlassian which suggested I create a bare repository to live on the server. What this means, although I didn’t entirely understand it at the time, is that there is no “current copy” of the files in this repository, it only keeps track of the information needed to re-create them. Since I wanted to have those files on my server for hugo to run on, this was not going to do.
My second attempt was better. I created a normal repository, by which I mean not bare, cloned it to my local machine, added the files that are used to generate my site, and committed locally. Then I attempted to push those changes back to my origin repository, on my server. This was the result:
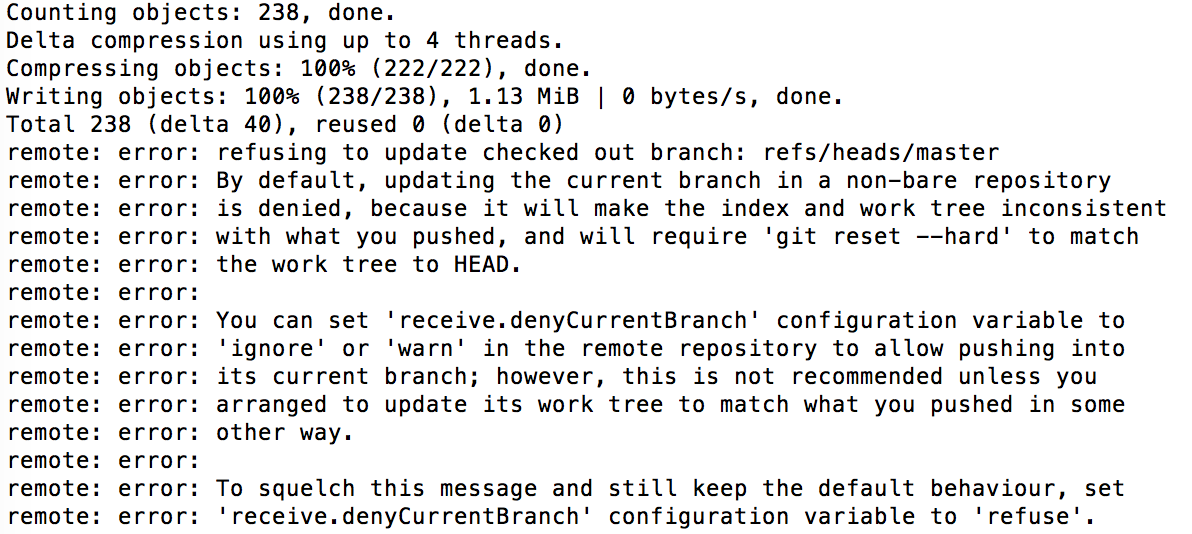
I am a little baffled by this error, honestly. I don’t understand what it means by making the index and work tree inconsistent. What it means in practice, though, is that I can’t push to another non-bare repository. What I’ve read implied I can pull, but that would involve the server being able to find my laptop, which is much more challenging than the reverse. So, here’s my question, then: Why doesn’t this work? It seems to me that the whole concept of git is to be able to move changes from peer repositories, so why can I not push, only pull?
What I ended up doing was creating a bare repository on the server, and cloning it twice, once to my laptop, once to my home dir on the server. I then set up a post-recieve hook on the bare repository to promt the server-local one to pull changes, and kick off a site-generation. This means that publishing is now a 1-step process, push changes!
I would also like to set up a cron job to re-generate the site once a day, so that if I have committed and pushed an article post-dated into the future, it will automatically publish when that date arrives, thanks to hugo being pretty darn neat.
I’d love to hear what you guys have to say about why I can’t push from repository to repository, and need a bare one in the middle to pull from, thanks for any wisdom you have to share!